周回遅れのrust-ndarray自主練4回目
D2Q9の速度ベクトル、重み、逆方向インデックスを以下のように定義します。
fn d2q9 () -> Array2< T> {
d2q9index ().mapv (| q| q as T)
}
fn d2q9index () -> Array2< I> {
arr2 (& [
[ 0 , 0 ],
[ 0 , 1 ],
[ 1 , 0 ],
[ 0 , - 1 ],
[- 1 , 0 ],
[ 1 , 1 ],
[ 1 , - 1 ],
[- 1 , - 1 ],
[- 1 , 1 ],
])
}
fn w () -> Array1< T> {
Array1 :: < T> :: from_iter (
[4. / 9. as T].into_iter ()
.chain (
[1. / 9. ].into_iter ().cycle ().take (4 )
).chain (
[1. / 36. ].into_iter ().cycle ().take (4 )
)
)
}
fn opp () -> [U; 9 ] {
[0 , 3 , 4 , 1 , 2 , 7 , 8 , 5 , 6 ]
}
粒子の取りうる速度の方向が9つあり、それぞれy,x方向への速度を持ちます。
平均分布関数を求めるための重みを9つの方向に以下のように割当てます。
逆方向インデックスにはバウンスバック時に180度跳ね返す先のインデックスを設定します。
まずは初期状態を作ります。
type T = f32 ;
type U = usize ;
type I = isize ;
pub fn vortex_lbm2dmix (
ny : U,
nx : U,
viscosity: T,
v0 : T,
barrier : impl Iterator < Item= (U, U)>
+ Clone
) -> impl Iterator < Item= Array2< T>> {
let omega = 1. / (3. * viscosity + 0.5 );
let (c, ci) = (d2q9 (), d2q9index ());
let (w, opp) = (w (), opp ());
let v0p2 = v0* v0;
let mut f = Array3 :: < T> :: zeros ((9 ,ny,nx));
{let arr = Array2 :: < T> :: ones ((ny,nx));
(0 ..9 )
.for_each (| i| {
let cv = c[(i, 1 )] * v0;
f.slice_mut (s! [i, .., ..]).assign (& (
w[i] *
(& arr + 3.0 * cv + 4.5 * cv* cv - 1.5 * v0p2)
))
});
}
配列のメモリレイアウトの選択は結構大事で体感でも違いがわかります。
また、タイプエイリアス は本来こういう使い方でないのは重々承知しておりますゆえお気遣いなくお願い申し上げます。
バウンスバックは単純なものを使うので外部から障壁をイテレータ で受け取りメインループ前に対象インデックスと反対方向インデックスの対を作っておきます。
let bounceback =
Array1 :: < ((U, U, U), (U, U, U))>
:: from_iter (
iproduct! (
opp.iter ().enumerate ().skip (1 ),
barrier,
)
.map (| ((i, oi), (y, x))| (
(* oi,
(y as I + ci[(* oi, 0 )]) as U,
(x as I + ci[(* oi, 1 )]) as U,
),
(i, y, x)
))
.filter (| ((_,oy,ox), (_,y,x))|
* y < ny && * x < nx &&
* oy < ny && * ox < nx
)
)
;
並進…
(0 ..).scan (0 , move | _, _| {
iproduct! (1 ..9 , 0 ..2 )
.filter (| (i, j)| ci[(* i, * j)] != 0 )
.for_each (| (i, j)| {
rolla2v (
f.slice (s! [i, .., ..]),
ci[(i, j)],
j,
)
.assign_to (f.slice_mut (s! [i, .., ..]));
});
方向軸(1..9)と次元軸(0..2)をそれぞれ網羅し並進する方向へロールします。前回作成したオレオレroll関数が活きてきます。
並進後、バウンスバックして密度を求めます。
bounceback
.iter ()
.for_each (| (oidx, idx)| f[* oidx]= f[* idx]);
let p = f.sum_axis (Axis (0 ));
次に速度を求めます。
let vx =
(0 ..9 )
.filter (| i| ci[(* i, 1 )] != 0 )
.map (| i|
& f.slice (s! [i, .., ..]) * c[(i, 1 )]
)
.reduce (| sum, fc| & sum + & fc).unwrap ()
/ & p
;
let vy =
(0 ..9 )
.filter (| i| ci[(* i, 0 )] != 0 )
.map (| i|
& f.slice (s! [i, .., ..]) * c[(i, 0 )]
)
.reduce (| sum, fc| & sum + & fc).unwrap ()
/ & p
;
てな感じであとは衝突、流入 、渦度の出力と続きます。
こうして見てみると、方向軸の演算は独立しているので並列化がしやすいという評判もうなずけます。
あとは形だけならD2Q9をD3Q19などに拡張するのはたやすく行えます。
D3Q19の速度ベクトル、重み、逆方向インデックスは以下になります。
fn d3q19 () -> Array2< T> {
d3q19index ().mapv (| q| q as T)
}
fn d3q19index () -> Array2< I> {
arr2 (& [
[ 0 , 0 , 0 ],
[ 0 , 0 , 1 ],
[ 0 , 0 , - 1 ],
[ 1 , 0 , 0 ],
[- 1 , 0 , 0 ],
[ 0 , 1 , 0 ],
[ 0 , - 1 , 0 ],
[- 1 , 0 , - 1 ],
[- 1 , 0 , 1 ],
[ 1 , 0 , - 1 ],
[ 1 , 0 , 1 ],
[ 0 , 1 , 1 ],
[ 0 , 1 , - 1 ],
[ 0 , - 1 , 1 ],
[ 0 , - 1 , - 1 ],
[- 1 , - 1 , 0 ],
[ 1 , 1 , 0 ],
[ 1 , - 1 , 0 ],
[- 1 , 1 , 0 ], NB
])
}
fn w () -> Array1< T> {
Array1 :: < T> :: from_iter (
[1. / 3. as T].into_iter ()
.chain (
[1. / 18. ].into_iter ().cycle ().take (6 )
).chain (
[1. / 36. ].into_iter ().cycle ().take (12 )
)
)
}
fn opp () -> [U; 19 ] {
[0 , 2 , 1 , 4 , 3 , 6 , 5 , 8 , 7 , 10 , 9 ,
12 , 11 , 14 , 13 , 16 , 15 , 18 , 17 ]
}
プログラム的には4次元にするのも難しくなさそうですが今度はお手本となるモデルが見つかりません。
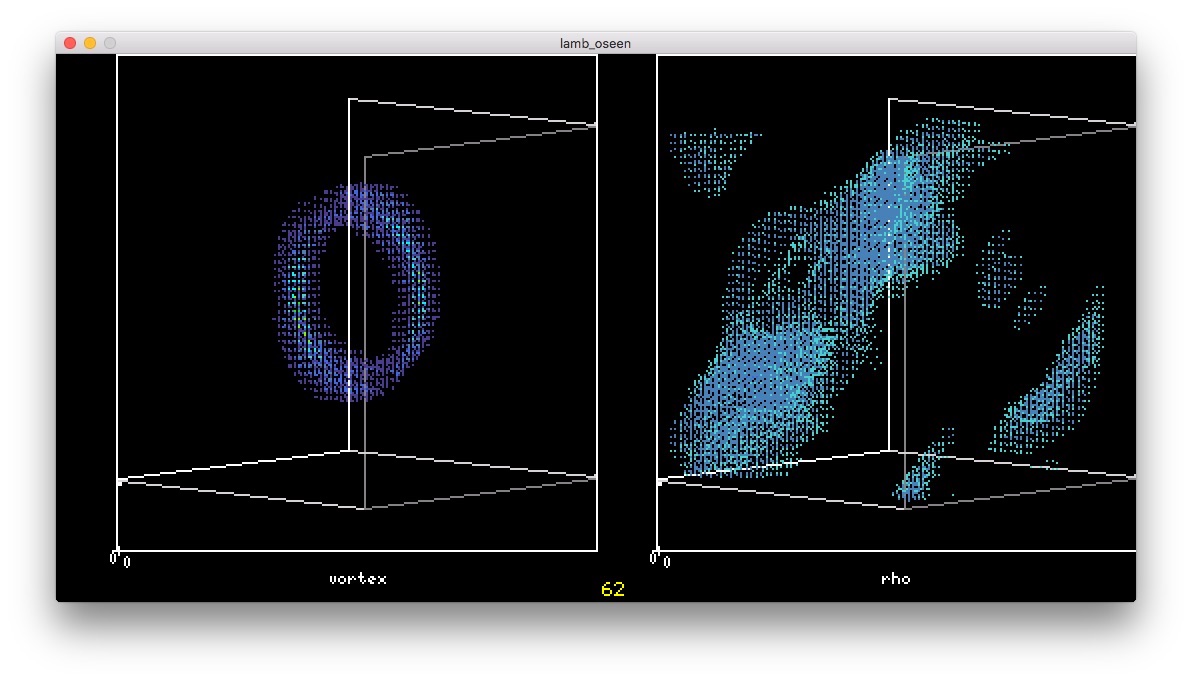
出来上がり
VIDEO
CFDPractise
|--CFDPython
| |--cavityflow2d
| |--cavityflow3d
| |--simulation
| | |--draw-cavityflow2d
| | |--draw-cavityflow3d
| | |--graph_supply_quiver2d
| | |--graph_supply_quiver3d
| | |--graph_supply_vortex_lbm
| | |--graph_supply_vortex_lbm3d
| | | ※グラフ供給
| | |--graph_supply_vortex_lbm_arrow
| | |--sdl2-draw-cavityflow2d
| | |--sdl2-draw-cavityflow3d
| | |--sdl2-draw-vortex_lbm
| | |--sdl2-draw-vortex_lbm2dmix
| | | ※SDL2での表示(改悪2D)
| | |--sdl2-draw-vortex_lbm3d
| | | ※SDL2での表示(改悪3D)
| | |--sdl2-draw-vortex_lbm_arrow
| |--vortex_lbm
| |--vortex_lbm2dmix
| | ※格子ボルツマン法 改悪2D
| |--vortex_lbm3d
| | ※格子ボルツマン法 改悪3D
|--ndarray_aulait
内部依存クレート
emb_arrowgraph
emb_bargraph
emb_linetrim
emb_shapegraph
linspacef32
wio_sbcamera_ortho
wio_sbeye
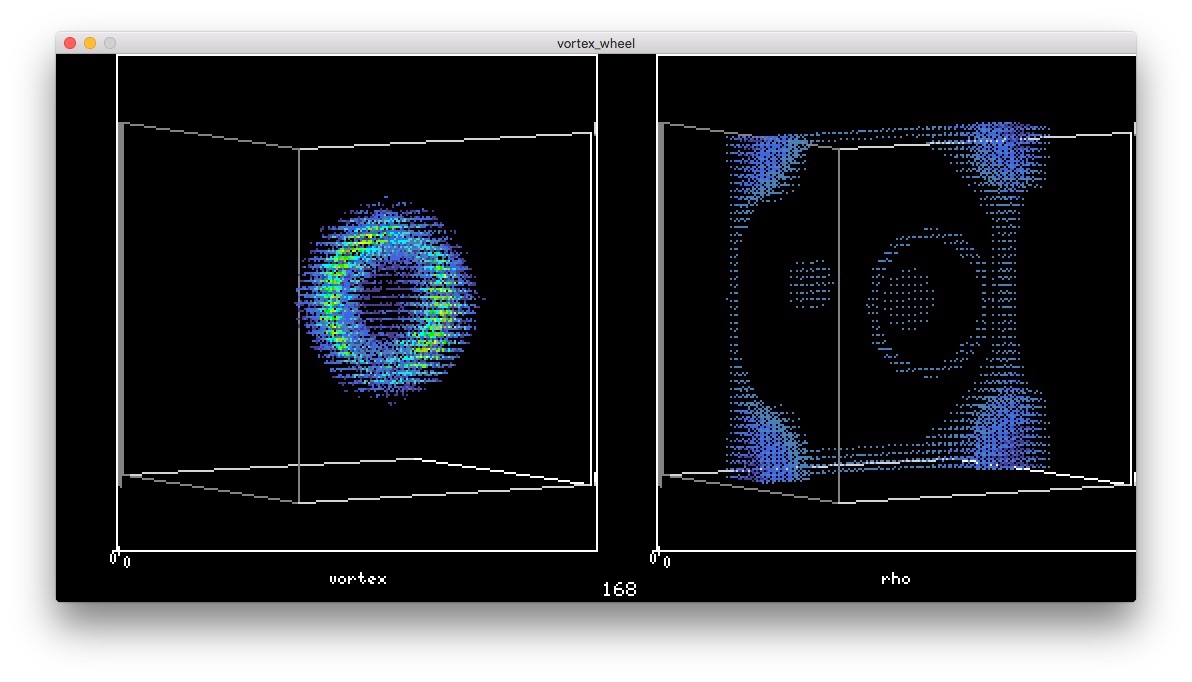
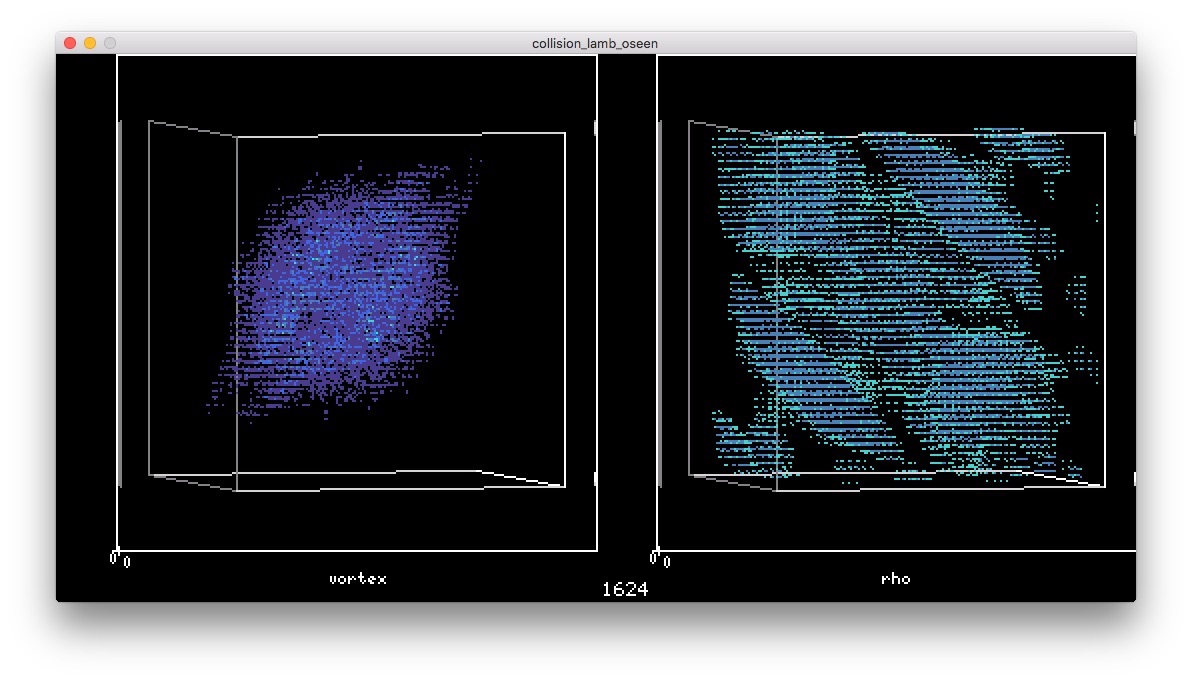
 ぶつかって
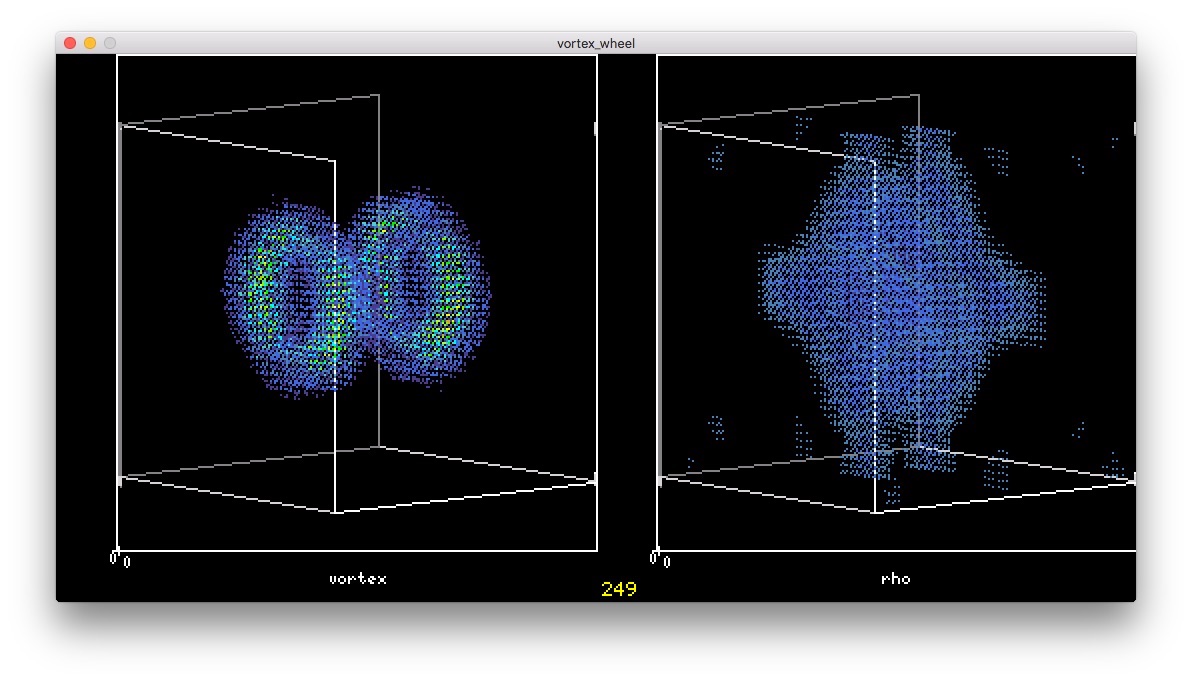
ぶつかって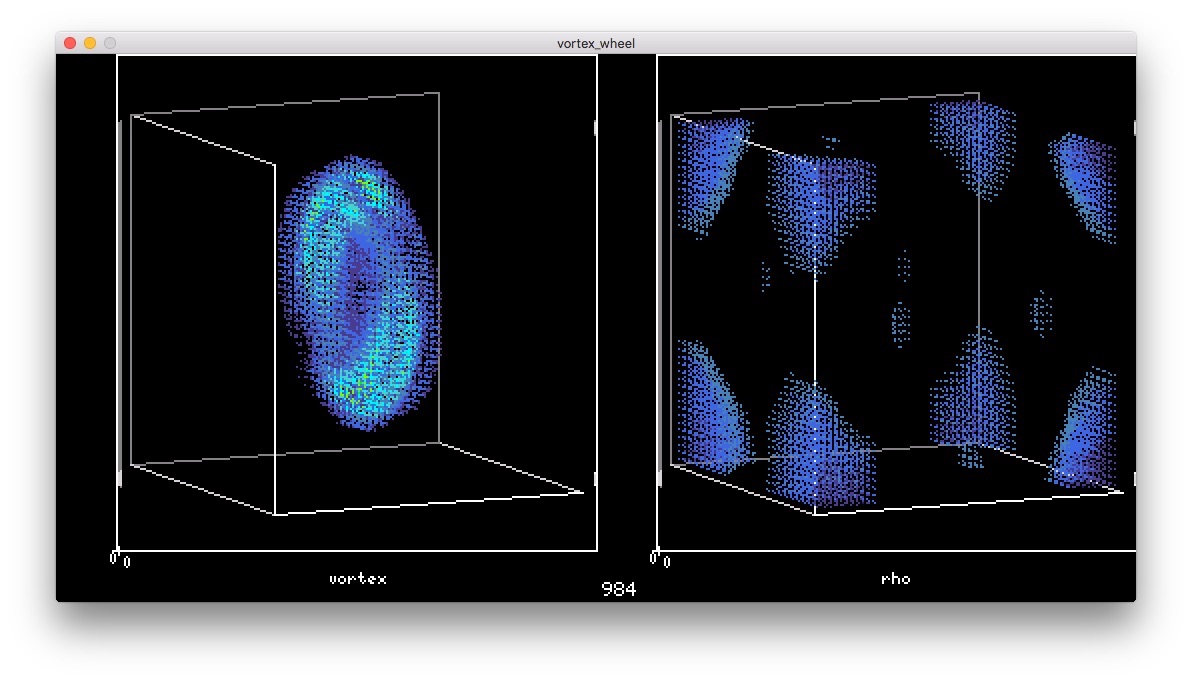 大きくなった
大きくなった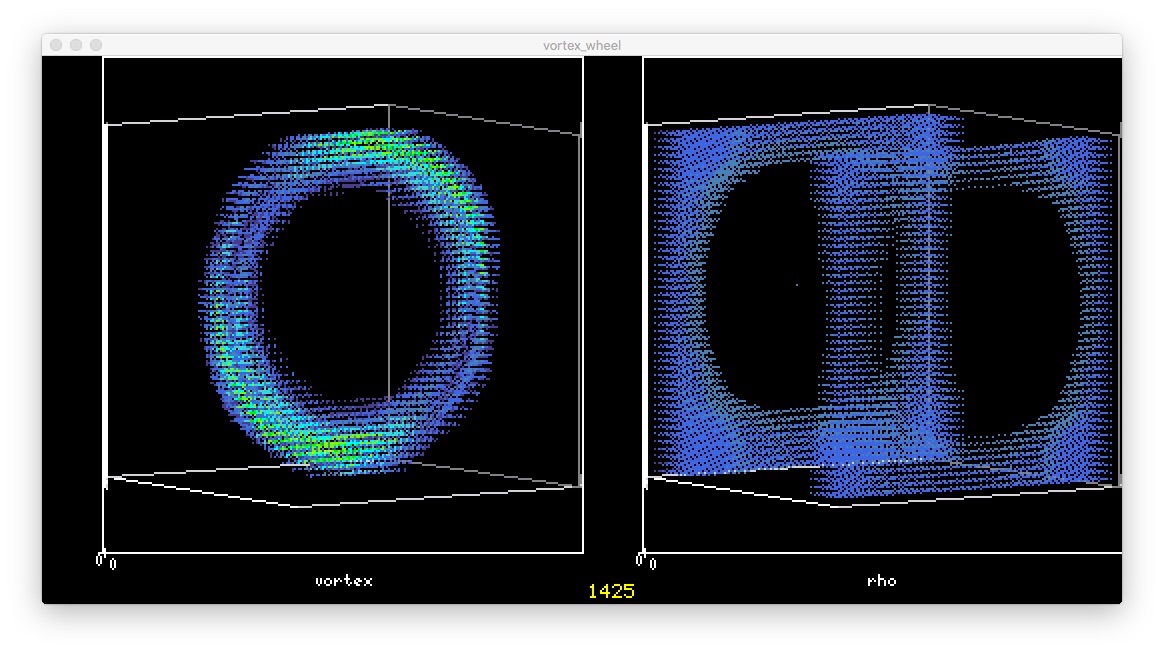
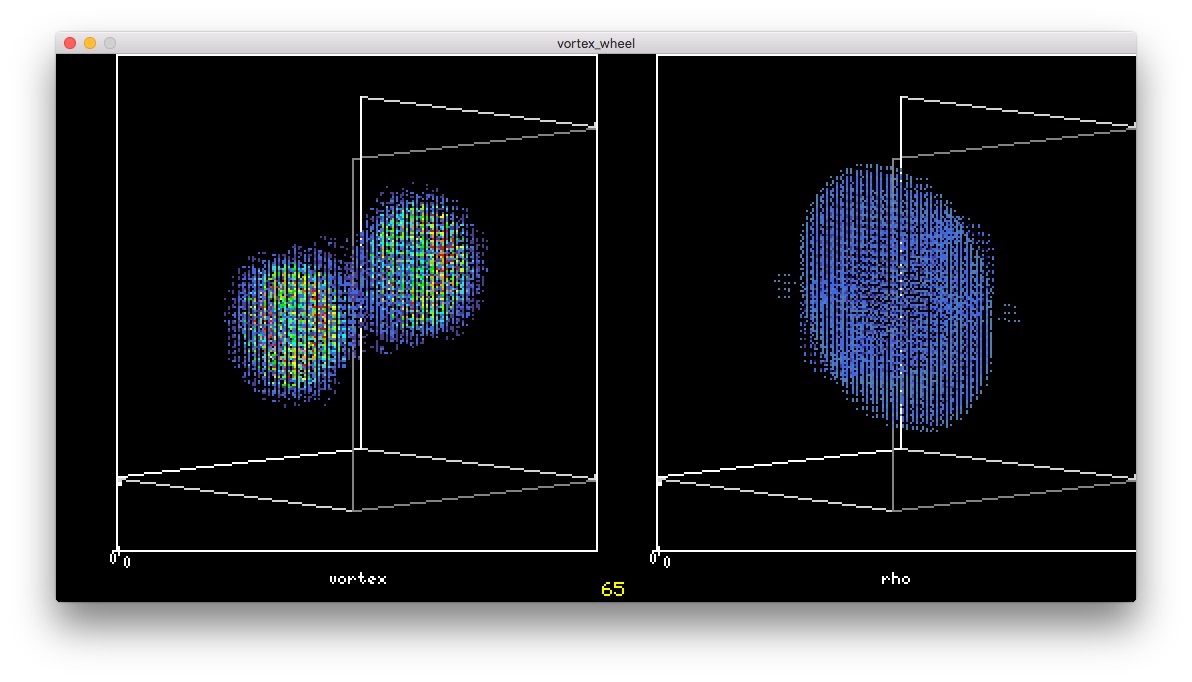 斜めになって
斜めになって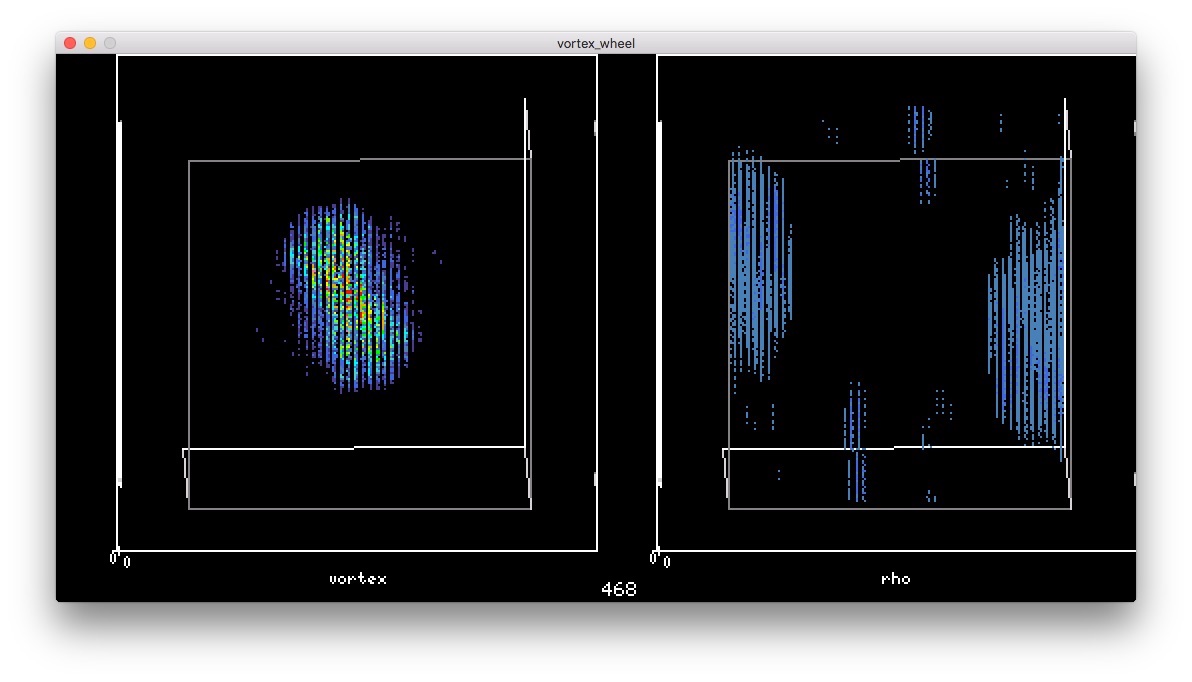 六角形になった。土星の極みたい。
六角形になった。土星の極みたい。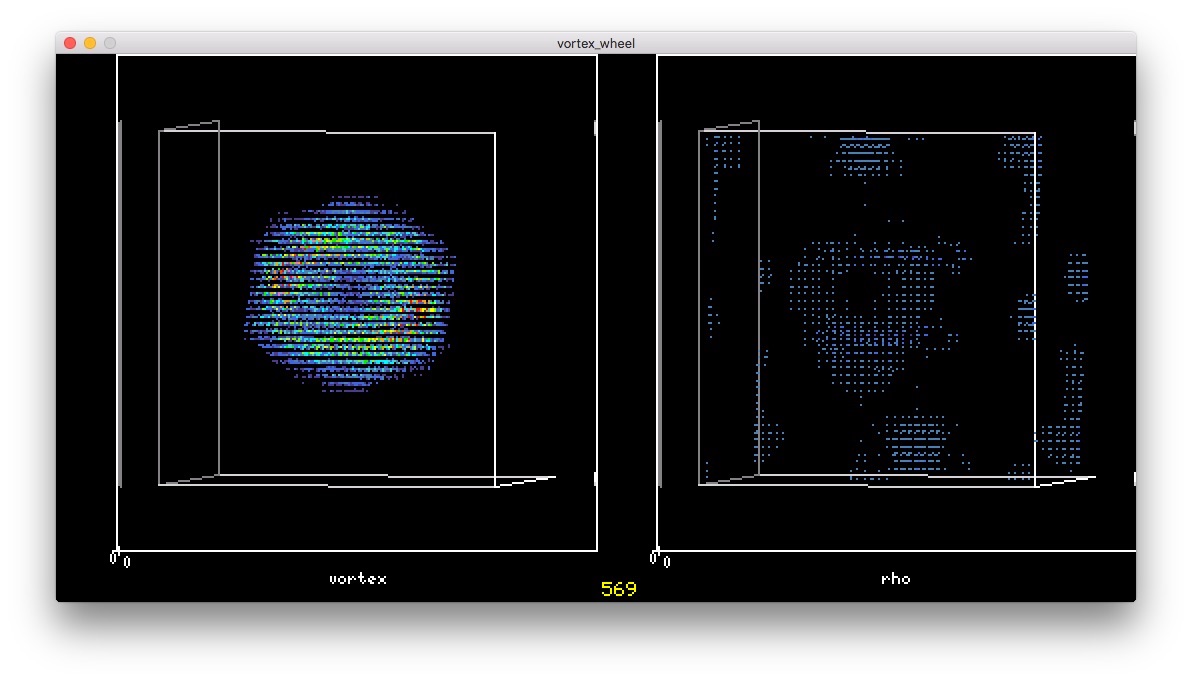
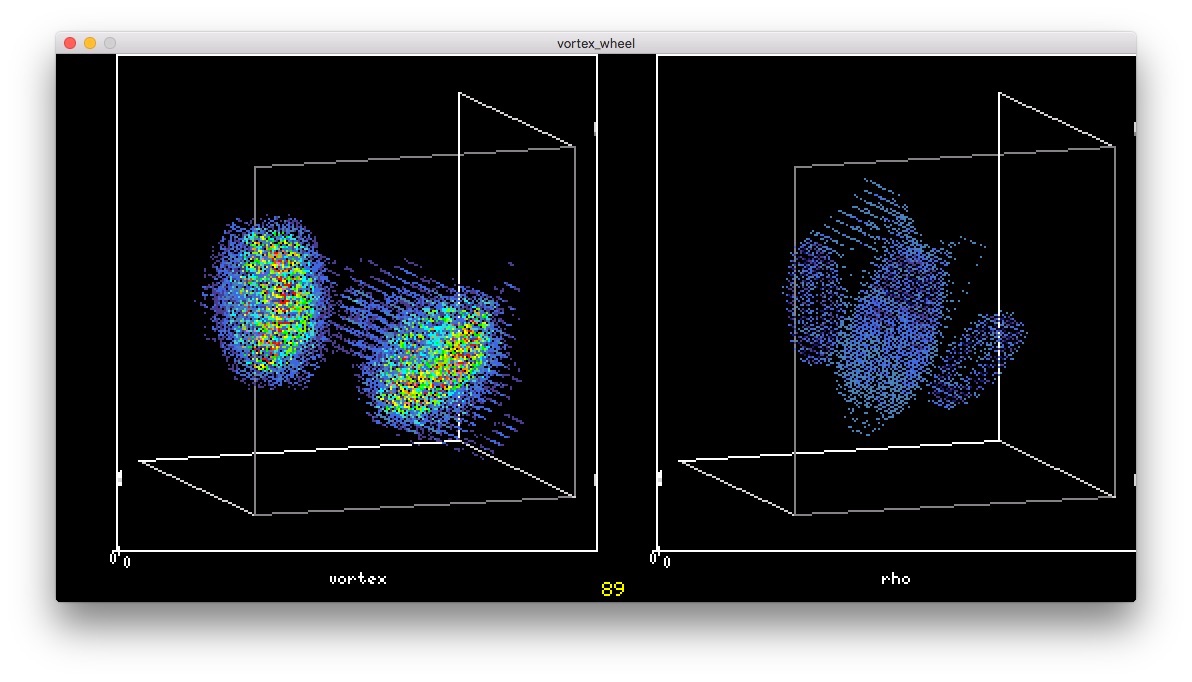 中間の角度になった
中間の角度になった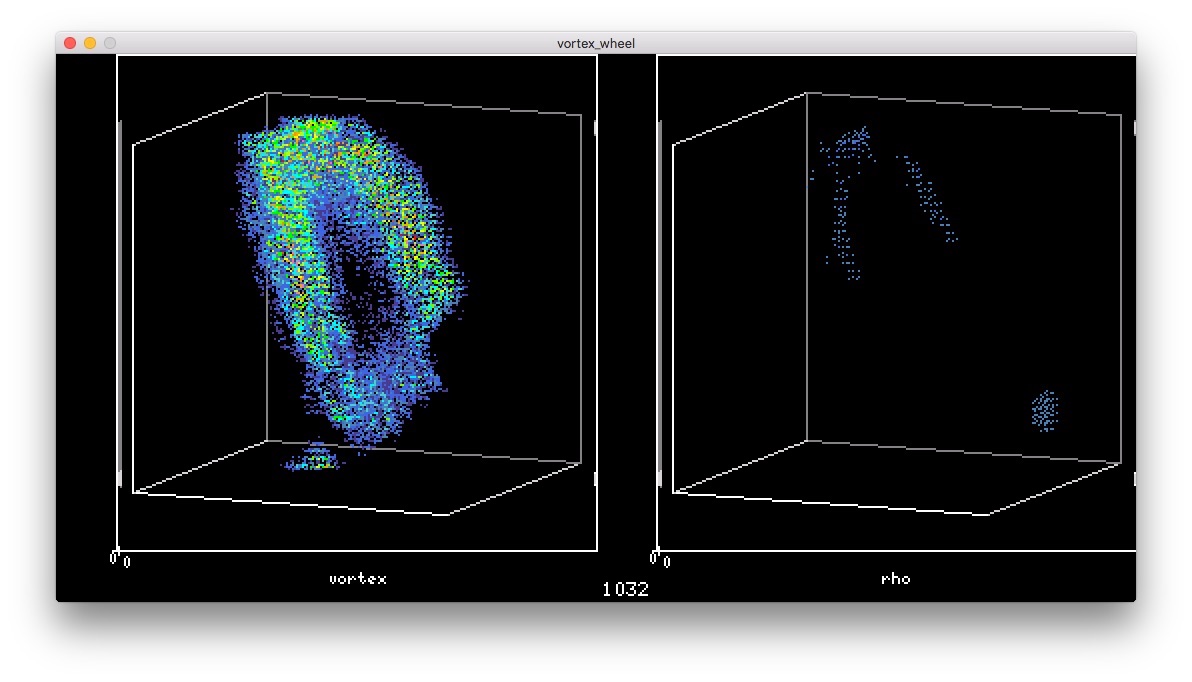
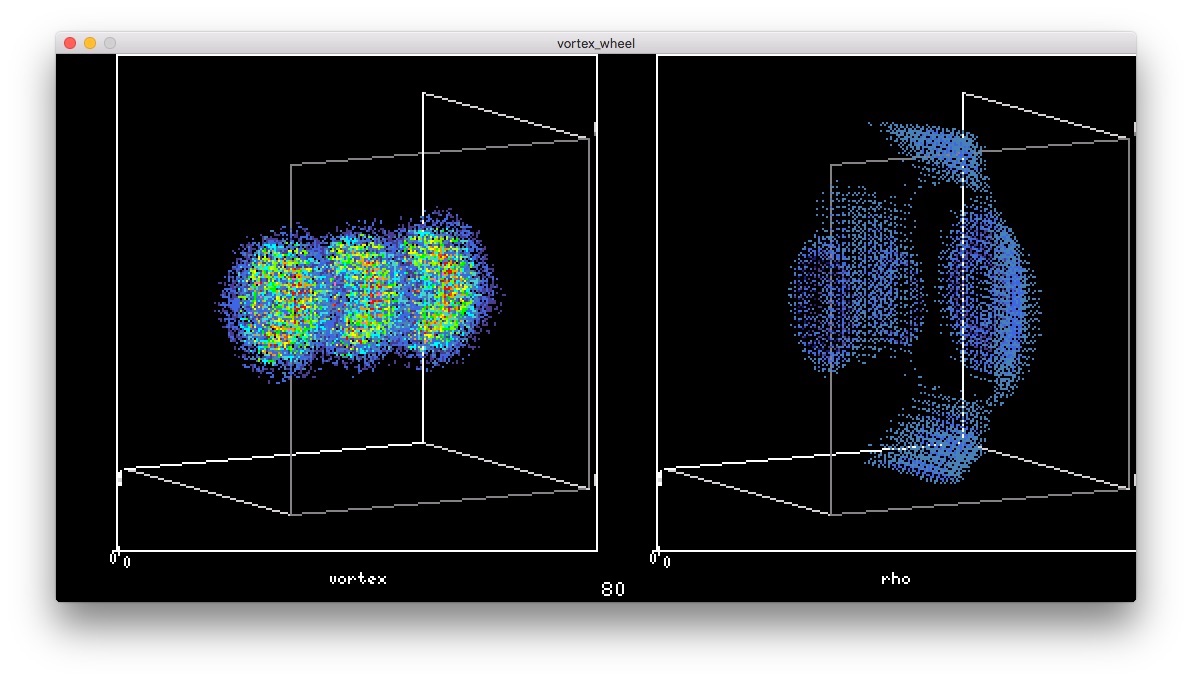 最初の2つがさきに合体
最初の2つがさきに合体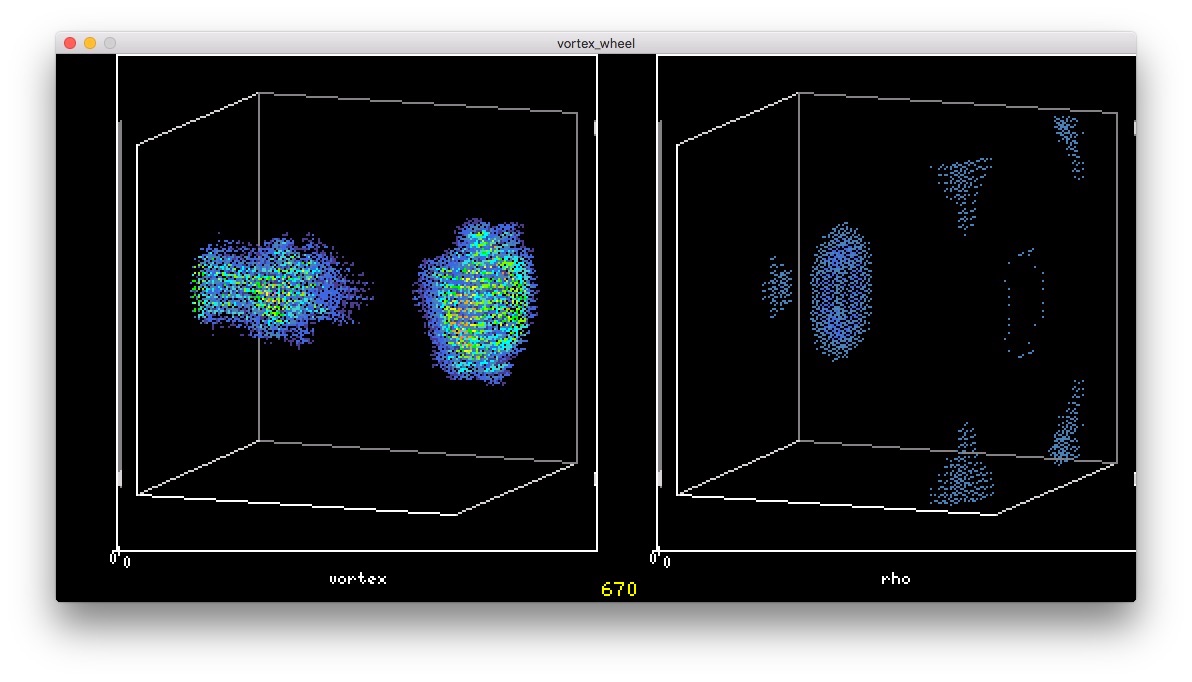 ドムの顔みたいな形になった
ドムの顔みたいな形になった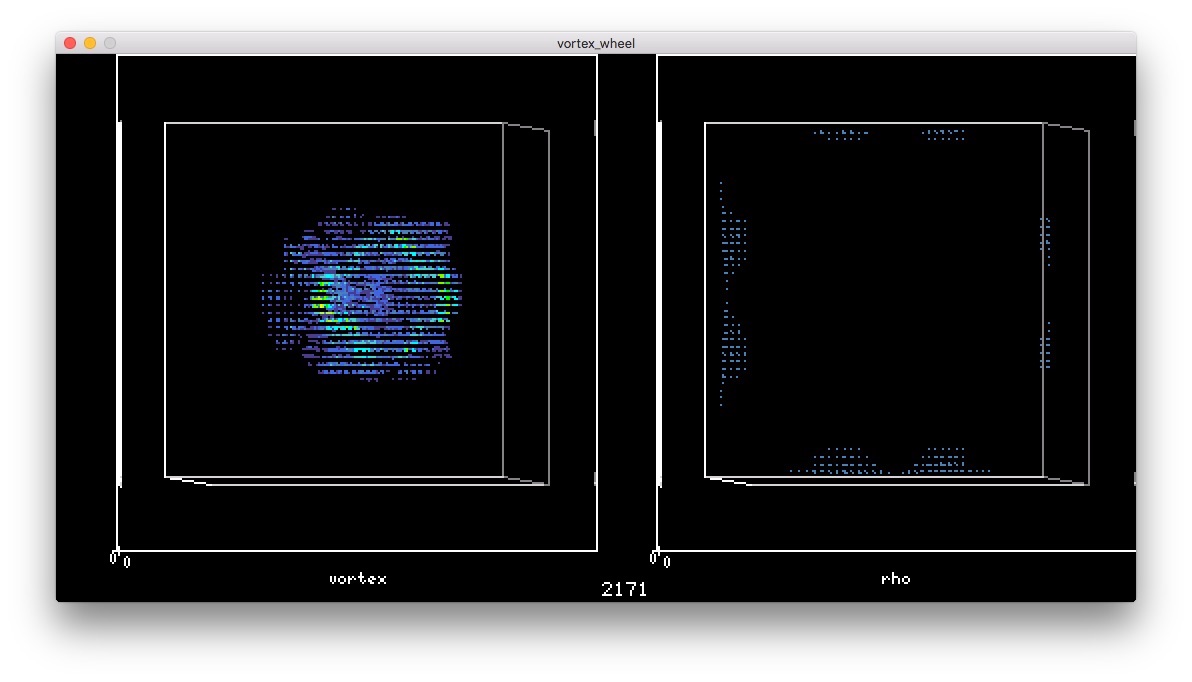 Xが現れた
Xが現れた
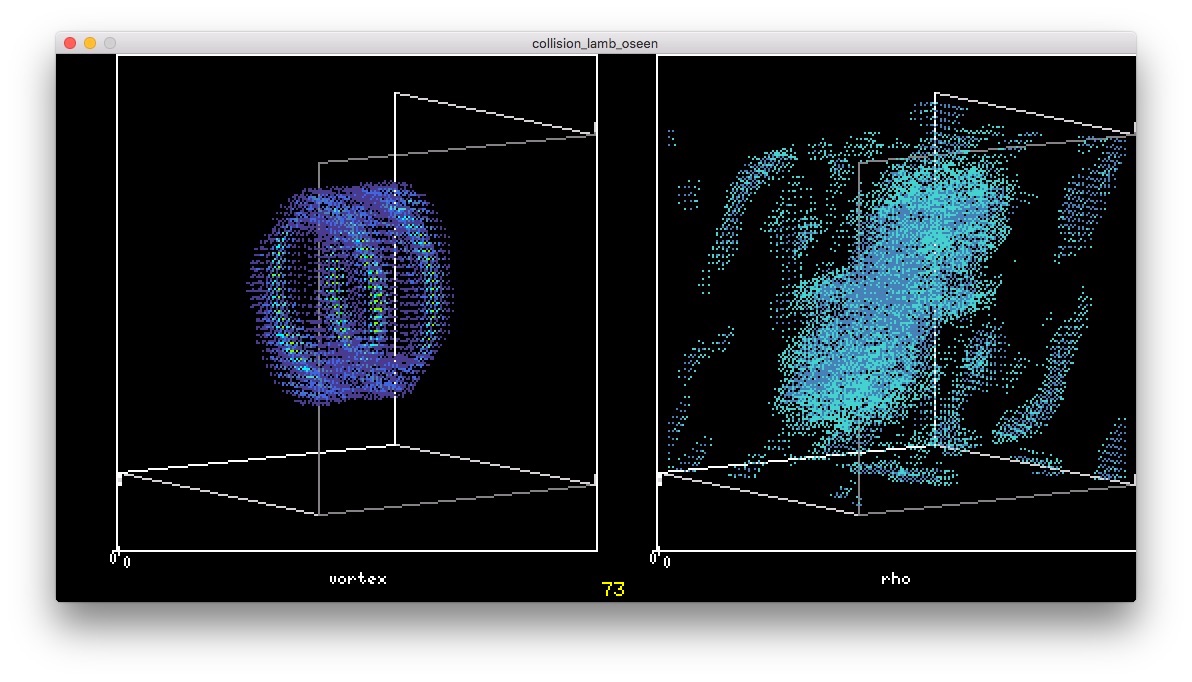 衝突 というより融合
衝突 というより融合